
前言
最近大學剛上第二學期,我發現機器學習算是挺難的一個科目。剛好我覺得可能會有人對機器學習感興趣,但不知道怎麽下手,或者想要大概看一眼機器學習是個什麽東東,再決定要不要深入學習。所以我想要基於大學講義,寫一篇對新手比較友好的文章,帶你揭開機器學習的神秘面紗~
當然,我的講義是英文寫的,在翻譯的時候難免會有錯誤。在遇到專用名詞的時候,我都會附上英文名詞,也盡量用通俗易懂的方式講解。這篇文章假設你已經有一定的編程基礎,但是不需要對機器學習方面有任何經驗。
準備好的話,我們就開始囉!
到底什麼是「學習」?
在開始聊「機器」學習之前,我們不妨先退一步想想:一般所謂的「學習」到底是什麼意思?
諾貝爾獎得主 Herbert Simon 曾給過一個很精準的定義:「任何讓系統透過經驗,進而提升效能的過程。」 這句話非常直白,而且不僅適用於人類,套用在電腦上也完全講得通。
當我們希望機器去「學習」並不斷進步時,丟給它們的任務通常可以分成兩大類:
- 分類 (Classification) : 把東西歸類到不同的標籤下(例如:「這封 email 是不是垃圾郵件?」)
- 問題解決 / 規劃 / 控制 (Problem solving / Planning / Control) : 採取一連串的行動來達成某個目標(例如:「機器人該怎麼走才能離開迷宮?」)
機器學習、AI 到底差在哪?
在看新聞或滑文章時,你可能常看到人工智慧 (AI)、機器學習 (ML)、深度學習 (DL) 和資料科學 (Data Science) 這幾個詞被混著用。雖然它們彼此相關,但其實不完全一樣。
你可以把它們想像成一組同心圓:
- 人工智慧 (AI) 是最廣泛的概念。它指的是創造能夠模仿人類智慧行為的機器。需要注意的是,AI 只在乎結果看起來聰不聰明,不在乎背後是怎麼做到的。如果你今天讓工程師寫個幾千行 if-else,那也算AI。事實上,在電腦發展的前幾十年,大家都是這樣寫 AI 的。
- 機器學習 (ML) 是 AI 的一個分支。跟人工手寫 if-else 規則不同,ML 是讓系統自己從資料裡面找出規律,然後用這些規律來做預測或決策。
- 深度學習 (DL) 又是機器學習的再往下一個分支,主要是用多層的「神經網路」來處理像影像辨識、自然語言處理等超複雜的問題。
- 資料科學 (Data Science) 則與上述所有領域都有交集。它是一門更廣的學科,涵蓋了怎麼用統計學、科學方法和演算法,從資料裡挖出有價值的資訊。
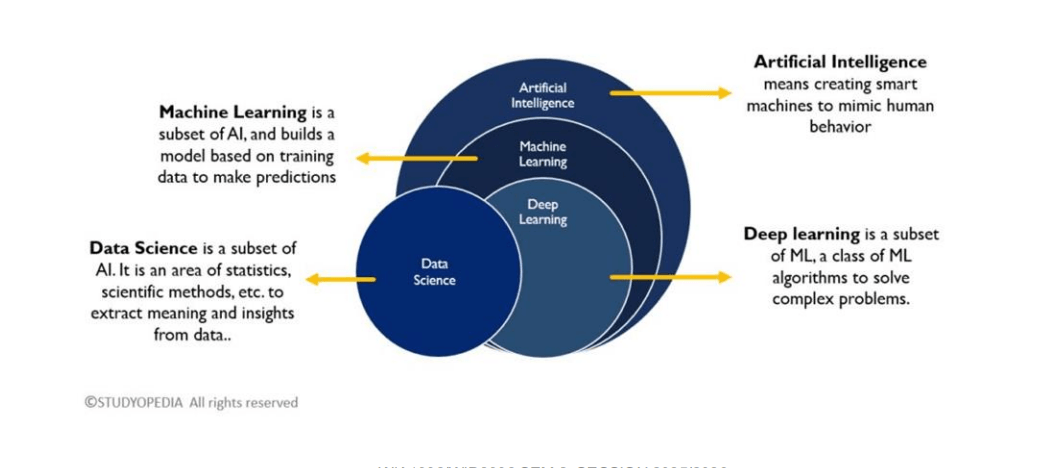
簡單來說:機器學習的重點在於「用訓練資料建立模型來做預測」,而不是靠人去手寫規則。
機器學習的四大種類
根據電腦系統學習的方式,我們可以把機器學習分成幾個主要類別:
- 監督式學習 (Supervised Learning) : 就像你給模型看題目和標準答案。你餵給模型一堆附帶答案的範例,讓它自己去搞清楚輸入和輸出之間的關係。這包含了預測連續數字的「迴歸」(Regression,像是預測房價),以及預測類別的「分類」(Classification,像是分辨垃圾郵件)。
- 非監督式學習 (Unsupervised Learning) : 模型只拿到一堆沒有標準答案(標籤)的資料,必須自己找出裡面的架構。這裡最常見的任務是「分群」(Clustering),把長得像的資料分在同一組。
- 強化學習 (Reinforcement Learning) : 模型透過與環境互動來學習。它會採取行動,然後得到獎勵或懲罰,最後慢慢試出最好的策略。你可以想像成用零食跟指令在訓練狗狗。
- 自監督式學習 (Self-Supervised Learning) : 這算是比較新的玩法。模型會根據資料本身「自己生出標籤」,幫自己出考題(例如把句子裡的某個單字挖空,然後叫模型練習預測那個字是什麼)。
實際應用
分類應用範例
分類在我們的日常生活中無所不在:
- 醫療診斷 : 這張 X 光片是否有肺炎的跡象?
- 垃圾郵件過濾 : 這封 email 該收進收件箱還是垃圾信箱?
- 詐欺偵測 : 這筆信用卡交易是否可疑?
- 推薦系統 : 你可能會喜歡聽哪首歌、看哪部電影?
- 語音與手寫辨識 : 將口語或手寫文字轉換為數位文字。
問題解決 / 規劃 / 控制範例
在這些任務中,代理程式 (Agent) 會根據環境自己採取行動來達成目標:
- 下西洋棋、圍棋等棋盤遊戲
- 開在路上的自動駕駛汽車
- 控制機器人或遊戲角色
- 無人機或直升機的自主飛行
定義學習任務的萬用公式:T、P、E
當你想構思一個機器學習的專案時,Tom Mitchell 提出的一個框架超好用。每一個學習任務都可以用三個元素來定義:
- T (任務, Task) : 你想讓系統嘗試做什麽?
- P (效能, Performance) : 我們應該如何衡量成功與否?
- E (經驗, Experience) : 系統要從什麼資料中學習?
這裡有幾個具體的範例:
| 任務 (T) | 效能 (P) | 經驗 (E) |
|---|---|---|
| 下西洋跳棋 | 贏得比賽的概率 | 自我對弈的練習賽 |
| 辨識手寫單字 | 正確分類單字的概率 | 一堆有標註標準答案的手寫圖檔 |
| 在高速公路上駕駛 | 發生人為判定錯誤前的平均行駛距離 | 記錄人類駕駛的影像與方向盤指令 |
| 垃圾郵件分類 | 正確分類電子郵件的概率 | 帶有人工標籤的電子郵件資料庫 |
在開始任何機器學習專案之前,這個框架非常適合用來釐清思緒。問問自己:我的 T、P 和 E 分別是什麼?
設計學習系統
當你著手建立一個機器學習系統時,有四個關鍵的設計決策:
- 選擇訓練經驗 : 系統將從哪種資料中學習?是直接的(有標籤的輸入-輸出對),還是間接的(例如只知道一盤棋最後的輸贏,但不知道中間每一步的好壞)?
- 選擇目標函數 : 系統究竟應該學習什麼?以跳棋程式為例,它要學的可能是一個「評估函數」,用來給當下的棋盤局勢打分數。
- 選擇表達方式 :這個目標函數要長什麼樣子?可以是查詢表 (lookup tables)、線性函數 (linear function)、決策樹 (decision tree)、神經網路等 (neural network)。
- 選擇學習演算法 : 系統要用什麼方法去找到那個「最好的函數」?這可能是梯度下降法 (gradient decent)、動態規劃 (dynamic programming)、演化演算法等 (evolutionary algorithms)。
具體範例:教電腦下西洋跳棋
好,理論講了一堆,我們來把所有東西串起來。我們來看一個經典的老例子:Arthur Samuel 在 1959 年寫的跳棋程式。這可是史上最早的機器學習系統之一。
目標函數 (Target Function)
我們想讓系統學到一個評估函數
- 如果這盤棋贏定了,
- 如果這盤棋輸定了,
- 如果是平手,
- 在其他情況下,
就等於如果雙方都完美發揮,最後能拿到的最佳分數。
但問題來了:要算出精確的
線性近似 (Linear Approximation)
我們可以把評估函數設計成各種「棋盤特徵」的加權總和:
其中:
= 基礎底分 (Bias),也就是即使棋盤上什麼特徵都還沒有,系統預設的初始局勢分數。 = 黑棋的數量 = 紅棋的數量 = 黑棋國王的數量 = 紅棋國王的數量 = 受到威脅的黑棋數量 = 受到威脅的紅棋數量
這些權重(
透過間接經驗進行訓練
因為我們是讓電腦自己跟自己下棋,沒辦法在它每走一步時都告訴它「這步得幾分」。取而代之的是,我們用時序差分學習 (Temporal difference learning):電腦會根據「下一步」的局勢預測,來修正「這一步」的分數估計。下了幾千幾萬盤之後,遊戲結尾那些很準確的分數,就會慢慢「回傳」並影響遊戲早期的步數。
想像你在打游戲。你不會每點一下滑鼠、每放一個技能,系統就立刻告訴你「這步 +1 分」或「這步 -1 分」對吧?你只有在最後輸掉的那一刻,才知道「啊,這局輸了」。
這種「只有最後結果,沒有中間每一步的評分」就叫做間接經驗。電腦在學下跳棋的時候也是這樣,它必須自己去覆盤思考:「到底是我開局第一步走錯,還是最後一步下錯,才導致最後輸掉的?」
LMS (最小均方) 演算法
為了一直調整權重,我們會用到「梯度下降法」。每看到一個訓練範例,就做兩件事:
- 計算誤差:
既然我們不知道這步真正該得幾分,我們就拿「下一步的預測分數」當作這步的臨時標準答案,我們稱之為。 - 更新每個權重:
在這裡,
補充説明:更新公式
還記得我們前面寫的評估函數嗎?
在機器學習的標準寫法裡,為了讓公式看起來更簡潔,我們會把
所以:
就是 :代表「黑棋的數量」。 就是 :代表「紅棋的數量」。 就是 :代表「黑棋國王的數量」。
舉個具體的例子:
假設你現在正下到一半(棋盤狀態
那麼,對這個棋盤
- 第 1 個特徵值
- 第 3 個特徵值
為什麼更新公式裡需要乘上
了解了
你看,要更新第
這是一個「誰惹禍,誰負責」的機制。
延續上面的例子,假設這步棋我們預測錯誤了,產生了誤差 (
- 黑棋國王的旋鈕 (
):
因為盤面上根本沒有黑棋國王 (),所以公式後半段會變成: 。
結果:完全不會被修改。
白話文:「這局上面根本沒有黑棋國王,所以這次預測失準絕對不是黑棋國王害的!不要動它的旋鈕!」 - 黑棋的旋鈕 (
):
盤面上有 5 顆黑棋 (),數字很大。公式後半段會變成: 。
結果:會被大幅度修改。
白話文:「畫面上有一大堆黑棋,結果我們分數還估錯,那『黑棋分數 ()』這個旋鈕肯定設錯了,趕快用力調一下!」
總結來說,
直覺上很簡單:
- 如果預測正確 → 不改變權重
- 如果預測太高 → 按比例減少權重
- 如果預測太低 → 按比例增加權重
在合理的情況下,LMS 保證能慢慢收斂,找到能讓均方誤差 (Mean Squared Error, MSE) 降到最低的那組權重:
註:公式裡的
想像你面前有一台電腦,上面有七個旋鈕(分別對應黑棋數量、紅棋數量等等)。
電腦一開始是瞎猜的。我們讓電腦給旋鈕亂填幾個數字。假設電腦預測這盤棋的局勢能拿 80 分,結果實際打完發現只有 50 分(預測太高了)。LMS 演算法其實就是一個**「旋鈕微調機制」**:它會告訴電腦,「你分數估太高了,去把剛才轉太高的那幾個旋鈕往回轉一點點」。每一次下棋都在微調旋鈕,下了幾萬盤之後,旋鈕就會被調到一個「預測最準」的位置。這就是 LMS 在做的事。
訓練資料從哪來?
訓練資料的來源和品質非常重要,常見的來源有這幾種:
- 環境提供的隨機範例(實務上最常見)
- 教師挑選的範例,專門挑最有學習價值的資料(例如「差一點就猜對」的例子)
- 主動學習 (Active learning),模型遇到不確定的題目時,主動去問人類專家標準答案
- 自主實驗 (Self-directed experimentation),學習系統自己設計實驗來找答案
做機器學習時有一個很大的假設,就是訓練資料和未來要預測的測試資料必須是獨立同分布 (Independently and Identically Distributed, IID) 的——白話文就是「它們必須來自同一個同溫層」。如果這個假設不成立,你就得用到像遷移學習 (Transfer learning) 或集體分類 (Collective Classification) 等更進階的技巧了。
補充説明:什麽是IID?
我們把這個詞拆成兩半來看:「獨立 (Independent)」 和 「同分布 (Identically Distributed)」。
同分布 (Identically Distributed)
打個比方:訓練題庫和最終考試的「範圍與難度」必須一樣。
機器學習就像是一個準備大考的學生。
- 訓練資料 = 你平常寫的模擬考題。
- 測試資料 = 你最終去考的學測或統測。
如果你的模擬考題都是「高中數學」,而最終的大考也是考「高中數學」,我們就說這兩批資料是**「同分布」**的。因為它們背後出題的規則、範圍、難度都是一致的。學生(機器學習模型)只要平常練習得夠好,大考就能考高分。
什麼情況下是「不同分布」?
假設你平常寫的模擬考題都是「小學算術」(訓練資料),結果大考當天發下來的考卷是「大學微積分」(測試資料)。 這時學生絕對會考零分,因為考題的「分布(規則與環境)」完全改變了。
獨立 (Independent)
每一筆資料都是相互獨立的,不會互相抄襲或影響。
想像一下你丟硬幣。你前一次丟出正面,會影響下一次丟出反面的機率嗎?不會。每一次丟硬幣都是一個全新的幾率,這就叫做**「獨立」**。
什麼情況下是「不獨立」?
想像你在預測明天的天氣或明天的股票價格。 明天的天氣,絕對跟「今天的天氣」有高度關聯;明天的台積電股價,絕對跟「今天的台積電股價」息息相關。
在這種情況下,資料點和資料點之間是「互相影響」的。如果你把這些資料打亂順序隨便餵給 AI,AI 會學得一塌糊塗,因為它忽略了資料之間「時間上的因果關係」。
目標函數可以長什麼樣?
不同的表達方式各有優缺點,主要就是在「表達能力」跟「好不好學」之間做取捨:
- 數值函數 : 線性迴歸、神經網路、支援向量機 (SVM)。這些非常擅長捕捉平滑、連續的模式。
- 符號函數 : 決策樹、邏輯規則。這種生出來的模型人類比較看得懂。
- 基於實例的函數 : 最近鄰演算法 (Nearest-neighbor)、基於案例的推理。它遇到新問題時,會去翻舊筆記,找最像的範例來參考。
- 機率圖模型 : 貝氏分類器 (Naïve Bayes)、貝氏網路、隱馬可夫模型。這類方法可以直接把變數之間的不確定性跟依賴關係建進模型裡。
一個模型的表達能力越強,能處理的問題就越複雜,但也代表你需要餵給它更多的資料,它才能學得準確。這是機器學習裡永遠逃不掉的取捨。
評估學習系統
訓練完一個模型之後,你怎麼知道它到底行不行?主要有兩種方法:
- 實驗評估 : 拿一組標準的資料集,用交叉驗證 (Cross-validation) 來做對照實驗。看的指標包括測試準確率、訓練時間、預測速度等等。然後用統計檢定來確認不同方法之間的差異到底是真的還是碰巧。
- 理論分析 : 用數學去證明這個演算法的能耐。例如它的運算複雜度、擬合能力、樣本複雜度 (Sample complexity)(到底需要多少資料才能學得夠好) 等等。
實務上,大部分 ML 工作兩種都會用到。
重點回顧
- 機器學習是關於從經驗中學習 : 使用資料來逼近函數,而不是靠人工編寫規則。
- 所有機器學習問題都能拆成 T、P、E:任務、效能指標、經驗。
- 設計系統的四個選擇:訓練經驗、目標函數、表達方式、學習演算法。
- 模型的表達能力越強,需要的資料量就越大。
- 評估是關鍵:模型到底好不好,取決於它面對「沒看過的資料」時表現得怎樣。