資料前處理:為什麼清理資料這麼重要?
在我們訓練任何機器學習模型之前,必須先面對現實中亂七八糟的原始數據。資料前處理 (Data preprocessing) 就是把這些數據變成好看的報告的過程。想像一下,你在煮飯前總得先洗菜、切菜吧?如果食材又髒又沒切過,是做不出好菜的。
原始數據通常會有一堆問題,像是異常值 (outliers)、缺失值 (missing values)、無意義的組合,還有亂七八糟的單位。前處理就是要把這些混亂,變成模型真正能看得懂、學得會的東西。
資料前處理的 7 個步驟
1. 取得資料集 (Acquire the dataset)。 從各個來源收集資料,然後把它們整合成適當的格式。資料集的結構會根據你的領域而有所不同(比如商業資料跟醫療資料就長得不一樣)。
2. 匯入關鍵函式庫 (Import crucial libraries)。 在 Python 裡,有三個函式庫是前處理的鐵三角:NumPy(科學運算)、Pandas(資料操作與分析)和 Matplotlib(2D 繪圖跟視覺化)。
3. 匯入資料集 (Import the dataset)。 把資料載入你的工作環境。記得確認你的工作目錄 (working directory) 設定正確,程式才找得到檔案喔。
4. 處理缺失值 (Handle missing values)。 這點超級重要!如果你無視缺失資料,模型就會得出錯誤的結論。常見的做法包含用該欄位的平均數或中位數來填補,或是乾脆把缺漏的那一整列刪掉。
欄位?列?都是什麼?
為了更容易理解,我們可以把資料想像成一個 Excel 表格。在資料科學中,表格的兩個維度分別代表:
- 欄位 (Column / 垂直方向): 代表一個特定的 「特徵 (Feature)」 或 「變數」。例如:每個人的「年齡」、「身高」或「收入」。
- 列 (Row / 水平方向): 代表 「一筆完整的資料 (Observation / Record)」。例如:某位特定使用者的所有基本資料。
實際範例解析
假設我們有一個如下的客戶資料表:
| 姓名 | 年齡 (欄位) | 收入 (欄位) |
|---|---|---|
| 小明 (這是一列 Row) | 25 | 50,000 |
| 小華 (這是一列 Row) | (缺失值) | 60,000 |
| 小美 (這是一列 Row) | 27 | 55,000 |
當我們提到用該欄位的平均數或中位數填補,它的執行動作如下:
- 系統發現「小華」的「年齡」空缺了。
- 系統會去尋找「年齡」這個欄位 (Column) 裡其他已知的數值(也就是小明的 25 歲和小美的 27 歲)。
- 計算這個欄位的平均數:
。 - 最後把 26 填入小華年齡的缺失值中。
而後半段提到的把缺漏的那一整列刪掉,則是另一種暴力的做法:只要發現小華有一項資料沒填(年齡缺失),就把「小華」這一整筆資料(Row) 直接從表格中剔除,連帶他完好的收入資料也不採納了。
5. 類別資料編碼 (Encode categorical data)。 機器學習模型是靠數學運作的——它們只懂數字,不懂「紅色」或「男生」這種標籤文字。編碼的方法有虛擬變數 (dummy variables)、標籤編碼 (label encoding,把類別變成整數) 以及獨熱編碼 (one-hot encoding,為每個類別建立二元欄位)。
6. 特徵縮放 (Feature scaling)。 當你的特徵範圍差超多的時候(例如年齡 0–100 歲 vs 薪水 0–1,000,000 元),有些演算法會被搞混。特徵縮放就是把變數標準化到同一個範圍裡。最常用的兩個方法是 Min-Max 縮放和標準化 (Standardization / z-score)。
7. 切割資料集 (Split the dataset)。 把資料分成訓練集 (training set)(給模型學習用)和測試集 (test set)(用來驗證模型好壞)。最常見的切法是跟著八二法則走:80/20,或者 70/30、60/40 也很常見。
其他的前處理技巧
除了這 7 個核心步驟,你可能還會遇到:
- 資料整合 (Data Integration) — 把來自不同來源系統的資料,合併成單一的資料集。
- 資料轉換 (Data Transformation) — 把資料從一種格式轉成另一種格式(e.g.: source system format → destination format)。
- 資料離散化 (Data Discretization) — 把連續數值變成離散的區間(比如把確切的年齡,變成「18–25 歲」、「26–35 歲」這種年齡層)。
第二部分:迴歸分析 — 預測連續數值
現在資料乾淨了,我們來看看怎麼做預測。先從一個經典的例子開始。
房價問題
想像一下,我們有一份包含 47 間房子的資料集,裡面有居住面積(平方英尺)跟價格(千元馬幣)。問題很簡單:給定一間房子的面積,我們能預測它的價格嗎?
這是一個監督式學習 (supervised learning) 的問題。我們有「輸入-輸出」的配對資料,並想找出它們之間的關聯規則。因為輸出(價格)是一個連續的數值,所以這具體來說叫作迴歸 (regression) 問題。
補充說明:連續的數值?迴歸?都是什麼?
連續的數值是可以無限細分、有大小之分的數字。它們通常是「測量」出來的,而不是一個一個「數」出來的。它包含了所有的小數和分數。比如,房價可以是 50 萬馬幣,也可以是 50.5 萬馬幣,甚至是 50.512 萬馬幣。只要儀器或計算夠精確,數字可以無限切分下去。生活中的面積、身高、體重、溫度、時間,都是連續數值。
相對的概念是「離散數值」(Discrete Value): 這是只能跳躍式出現、通常是整數的數字。例如:「這間房子有幾間臥室?」答案只能是 1 間、2 間或 3 間,不可能有 2.38 間臥室。
在機器學習的領域裡,只要你的目標是預測一個「連續的數值」,我們就把這個任務稱為「迴歸」。
迴歸的核心概念,就是在茫茫的數據資料中,找出一條**「最符合趨勢的線」**(Line of Best Fit),藉此理解輸入(面積)與輸出(價格)之間的數學關係。
數學符號約定
在深入之前,我們先來約定一下符號:
= 輸入特徵 (例如第 間房子的面積) = 輸出/目標變數 (例如第 間房子的價格) = 一筆訓練樣本 = 訓練樣本的總數 = 我們的假設函數 (hypothesis function), 也就是我們想學出來的預測器
我們的目標是:找到一個函數
線性迴歸 (Linear Regression)
最簡單的假設就是線性函數。
預測的房價 = (基本底價) + (面積的影響力 × 面積) + (臥室的影響力 × 臥室數)
這些
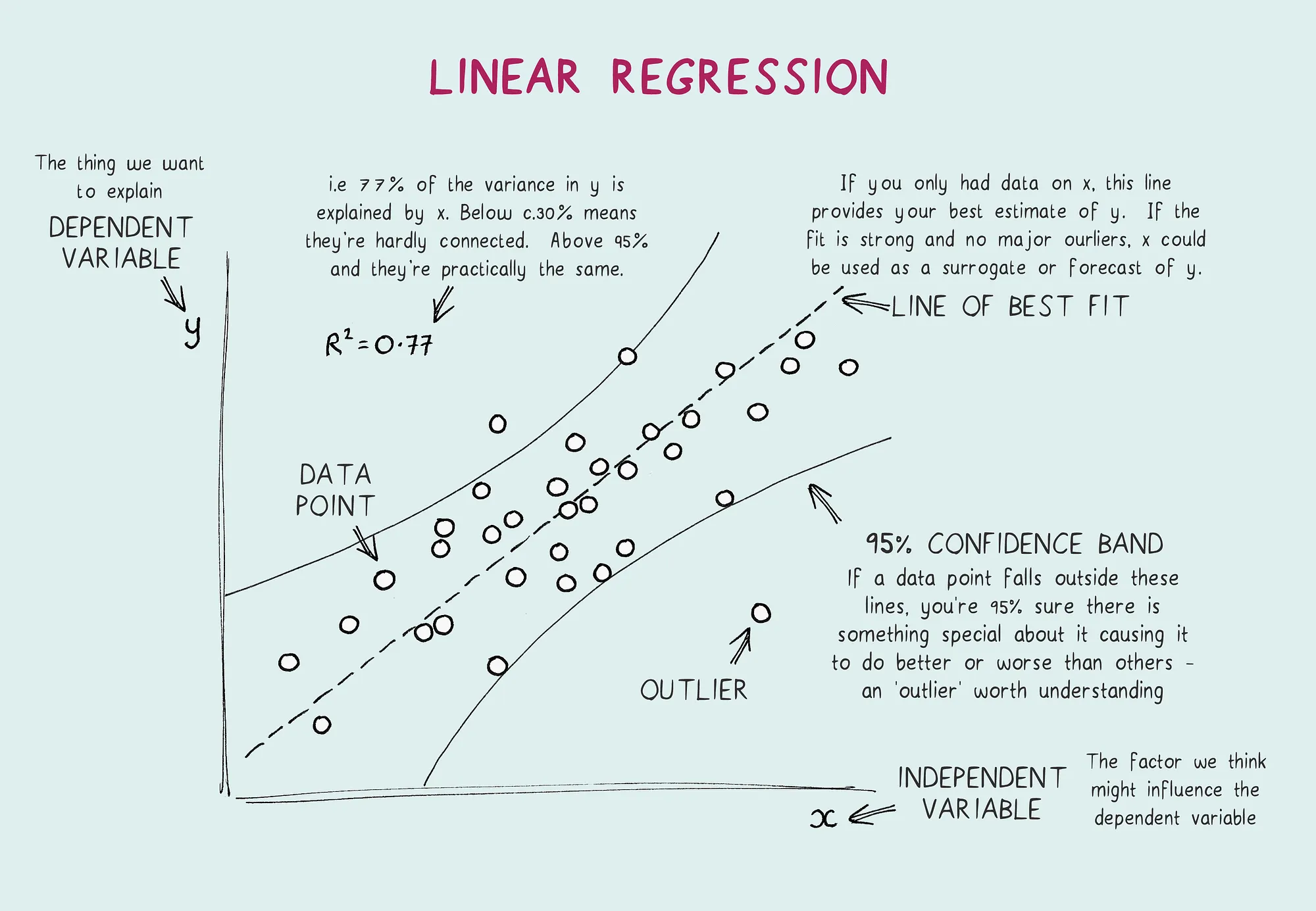
成本函數 (The Cost Function)
我們定義了一個最小平方法成本函
公式詳解:
把它們相減,就是在算**「我們猜錯了多少錢(誤差)」**。例如,我們預測賣 50 萬,實際賣了 60 萬,誤差就是 -10 萬。
2. 平方
這裡把誤差拿來「平方」,有兩個很重要的原因:
- 把負數變成正數: 如果我們高估了 10 萬(誤差 +10)或低估了 10 萬(誤差 -10),對預測來說都是一樣糟糕的。平方之後,負號就不見了,我們只看「誤差的幅度」。
- 嚴厲懲罰「大錯誤」: 平方有一個特性,會讓越大的數字膨脹得越快(例如 2 的平方是 4,但 10 的平方是 100)。這等於是在告訴機器:「小誤差還可以接受,但如果預測錯得太離譜,你的分數會扣得非常非常重!」
3. 加總
我們不能只看一間房子的誤差,而是要把資料集裡全部 47 間房子的「誤差平方」全部加起來,算出一個總分。這就是為什麼這個方法被稱為最小平方法 (Least Squares)。
為什麼前面要乘一個二分之一?其實這只是一個數學上的小偷吃步。 在機器學習的下一步,我們需要用到微積分來尋找最小誤差。當平方的那個 2 掉下來相乘時,剛好可以跟
梯度下降 (Gradient Descent) — 尋找最佳參數
梯度下降是一個迭代的優化演算法。它的直觀概念是這樣的:
- 隨便猜一個
的起始值。 - 計算成本
。 - 朝著能讓
減少最多的方向(最陡的下坡方向)稍微調整 θ。 - 重複這個動作,直到收斂(走到谷底)。
更新規則長這樣:
公式詳解
其實看不懂半點 我盡力說說看
想像一個情境:你被蒙住了雙眼,丟在一座高山上的某個地方。你的目標是「走到這座山的最低谷」。 你看不見,只能用腳感覺周圍地面的傾斜程度。你會怎麼做?你一定是用腳探一探,感覺哪邊是「最陡的下坡」,然後往那個方向踏出一步。接著再用腳感覺一下,再往最陡的下坡走一步。不斷重複,直到你覺得四周都平了,你就知道自己到達谷底了。
現在我們來看看我們的公式,把它拆開來看:
1.
: 這是我們的「權重」(例如:面積對房價的影響力)。你可以把它想像成你現在站在山坡上的**「座標位置」**。 : 在程式語言裡,這個符號唸作 "Assign"(賦值)。它的意思是**「把右邊算出來的新結果,取代掉左邊舊的東西」**。所以整行公式的意思是:「我的新位置,將會等於右邊算出來的結果」。
2.
- 這坨看起來最可怕的符號叫「偏導數」(Partial Derivative)。別管微積分了,它的白話文就叫作「坡度(slope)」。
- 它代表你現在腳踩的地方「有多陡」以及「哪邊是上坡」。如果山坡很陡,這個算出來的數字就很大;如果很平緩,數字就很小。
3. 減號
- 剛剛說偏導數算出來的是「上坡」的方向。但我們的目標是走到谷底(減少誤差),所以我們必須在公式裡加一個減號,強迫機器**「反著坡度走,往下坡前進」**。
4. α (Alpha,步伐大小)
- 這個
叫作學習率 (Learning Rate)。在下山的故事裡,它就是你的**「步伐大小」**。 - 機器在下山時,步伐不能亂踩。
- 如果
太大: 你的步伐太大,可能會一腳從山谷左邊直接跨到山谷右邊,甚至越爬越高,永遠找不到最低點。 - 如果
太小: 你用螞蟻的步伐下山,雖然很安全,但機器會算到天荒地老才走到谷底。
- 如果
所以公式,翻譯過來大概是:
新的位置 := 舊的位置 - ( 步伐大小 × 腳底下的陡峭程度 )
這裡的
把偏導數 (partial derivative) 展開,
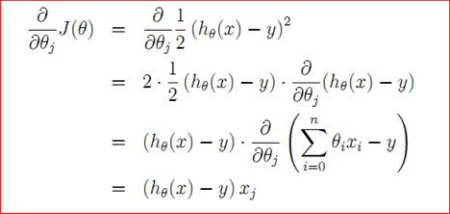
更新規則會變成:
公式詳解:
在第一個公式裡,我們告訴機器要「測量坡度」(
1. 準備更新位置:
這部分跟剛剛一模一樣:新的權重 := 舊的權重 + (步伐大小 × 調整方向)。
你可能會發現,這裡的符號從「減號 −」變成了「加號 +」。這是因為數學家在推導公式時,把後面的括號順序對調了,負負得正,就變成加號了。概念完全不變!
2. 預測的誤差:
是現實成交價。 是機器的預測價。
3. 這個特徵的「存在感」:
為什麼最後還要乘上一個
- 如果這間房子的面積超大(x 數值很大),那它對這次錯誤預測的「責任」就很大。乘上這個大數字後,面積的權重 (
) 就會被大幅度地調整。 - 相反地,如果今天這間房子根本沒有游泳池(游泳池數量 x=0),那房價算錯關游泳池什麼事?乘上 0 之後,游泳池的權重就不會被調整。
也就是,我要更新這個條件的重要性 (
這就是 LMS (Least Mean Squares) 更新規則,也叫作 Widrow-Hoff 學習規則。注意看一個細節:更新的幅度跟誤差是成正比的。當預測值很接近實際值時,調整的幅度就會很微小;當誤差很大的時候,調整的幅度就會很大。
批量 (Batch) vs 隨機 (Stochastic) 梯度下降
批量梯度下降 (Batch Gradient Descent) 會在做單次更新前,把所有訓練樣本的梯度加總起來。它很精準,但遇到大資料集的時候會跑得非常慢。

隨機/增量梯度下降 (Stochastic / Incremental Gradient Descent) 則是每看完一筆訓練樣本就立刻更新一次
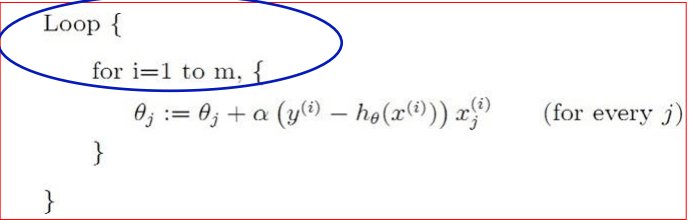
欠擬合 (Underfitting) vs 過擬合 (Overfitting)
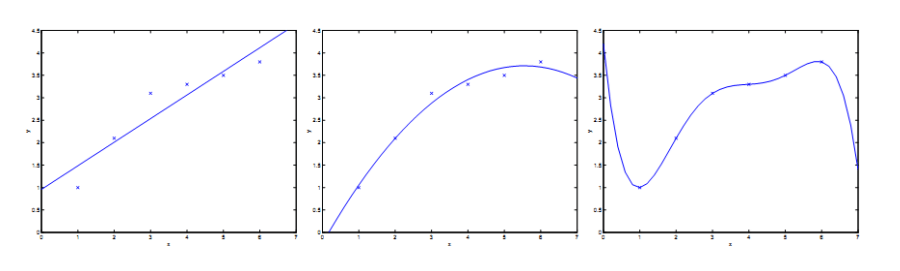
這是機器學習裡最重要的概念之一!想像一下用不同的模型來擬合我們的房價資料:
- 一條直線 (線性擬合) 可能太簡單了——它抓不到資料的真實弧度。這叫做欠擬合 (underfitting)。
- 二次方程式 (加上 x2) 擬合得比較好,抓到了更多結構。
- 五次方多項式 可以完美穿過每一個訓練資料點——但如果拿它來預測新房子的價格,結果一定會慘不忍睹。這叫做過擬合 (overfitting)。
一個只會死背訓練資料的模型,不一定是個好模型。我們要的是能對未知的新資料做出準確預測(具備泛化能力 generalization)的模型。
局部加權線性迴歸 (Locally Weighted Linear Regression)
一般的線性迴歸是用一條全域的線來擬合所有資料。局部加權線性迴歸 (LWLR) 換了個思路:在做每次預測時,它會給附近的訓練點比較大的權重,離得遠的點權重就給得比較小。
每個訓練樣本的權重通常會用高斯函數來算:
公式詳解:
這個應該不在考試範圍裡面,看個大概就行。
LWLR 就像是找了一個深耕當地的「資深房仲」。當你要賣一間 30 坪的房子時,這位房仲不會管那些 100 坪的豪宅賣多少錢,他只會特別去查「附近同樣也是 28 到 32 坪左右」的房子成交價,用這些極度相似的房子來幫你估價。
「差異程度」或「距離」:
- x 是你現在想估價的房子(例如:30坪)。
是資料庫裡的歷史成交房子(例如:一間 80 坪的房子)。 - 把它們相減再平方,算出來的就是這兩間房子的「差距有多大」。差距越大,這個數字就越大。
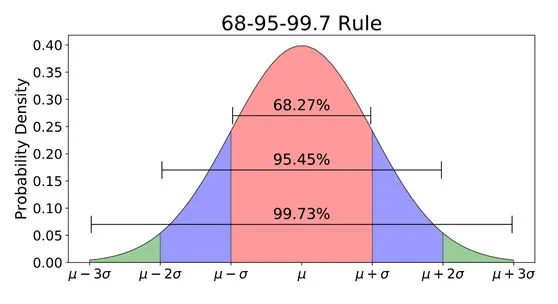
如果兩間房子很像(距離近): 算出來的權重
如果兩間房子差十萬八千里(距離遠): 這個函數會讓權重「墜崖式」地急速暴跌到趨近於 0。這等於房仲在說:「那間 80 坪的豪宅對我們這間 30 坪的估價毫無參考價值,直接忽略!」
「參考範圍」的大小:
這個
- 如果
很大: 鐘型曲線會很平緩。這代表房仲比較隨和,連 40 坪、50 坪的房子也會加減參考一下。 - 如果
很小: 鐘型曲線會非常尖銳、極度狹窄。這代表房仲非常嚴格,只肯參考 29.5 坪到 30.5 坪的房子,只要差一點點,權重就直接給 0。
什麼叫「無母數 (non-parametric)」?
一般的線性迴歸,機器只要把 θ0、θ1、θ2 這三個參數學好,它就可以把那 47 間房子的歷史資料全部刪掉了,因為規律已經濃縮在那三個參數裡。
但 LWLR 是「無母數」的,這意味著它沒有固定的公式參數。它就像一個不記筆記、全靠臨時抱佛腳的學生。每次有人來問一間新房子的價格,它就必須把那 47 間歷史資料全部拿出來重新比對一次、重新算一次附近的權重。雖然計算量變大很多,但它的預測會比一條死板的直線靈活且準確非常多!
參數
第三部分:邏輯迴歸 (Logistic Regression) — 當輸出是離散值
前面講的都是建立在
我們沒辦法用單純的線性函數,因為它有可能輸出小於 0 或大於 1 的值。所以,我們要把它包裝進 Sigmoid (邏輯) 函數裡面:
Sigmoid 函數可以把任何實數壓縮到 (0,1) 的範圍內,這樣我們就可以把它解釋成「機率」。如果 h(x)≥0.5,我們就預測 y=1;否則就預測 y=0。
公式詳解
**
它就像一台「數值壓縮機」。無論你把多大或多小的數字(哪怕是 +10000 或 −10000)丟進這個公式裡,它都會把它「擠壓」成一個介於 0 到 1 之間的小數。
為什麼要壓在 0 到 1 之間? 因為這正好就是「機率」! 如果公式算出來是 0.85,機器就是在告訴你:「我有 85% 的把握這是一封垃圾郵件(y=1)。」既然大於 0.5(50%),我們就大膽預測它是垃圾郵件。
擬合邏輯迴歸
這次我們不用最小化平方誤差了,而是改用最大概似估計 (Maximum Likelihood Estimation, MLE)。我們的假設是:
1. 第一個公式:預測「會發生」的機率
白話文翻譯:
「在我們已知這筆資料 (x) 和現在的模型標準 (θ) 的條件下,這件事**『會發生 (y=1)』**的機率是多少?」
答案: 就是我們的魔法壓縮機 h(x) 算出來的數字! 例如:模型算出來 h(x)=0.8,這行公式就是在說:「這封信是垃圾郵件的機率是 80%。」
2. 第二個公式:預測「不會發生」的機率
白話文翻譯:
「在同樣的條件下,這件事**『不會發生 (y=0)』**的機率是多少?」
答案: 因為結果只有「是」跟「否」兩種可能,既然全部的機率加起來必須是 100%(也就是數字 1),那麼「不會發生」的機率,當然就是 1 減掉「會發生」的機率!
延續上面的例子:既然是垃圾郵件的機率是 80% (0.8),那它是正常郵件的機率就是 1−0.8=0.2 (也就是 20%)。
它的對數概似函數 (Log-likelihood) 長這樣(推導過程省略)(應該也沒什麼用,看看就好):
公式詳解:
這串公式看起來很嚇人,但它其實是一個非常聰明的**「雙開關機制」**,完全根據現實的真相(y 是 1 還是 0)來決定怎麼評分:
- 如果這封信真的是垃圾郵件(
): 公式後半段的 會變成 ,後半段直接消失!公式只剩下 。這等於在說:「既然答案是 ,我只在乎你猜的機率 有多接近 。你越接近 ,分數越高。」 - 如果這封信是正常郵件(
): 公式前半段的 會消失!公式只剩下後半段的 。這等於在說:「既然答案是 0,我希望你猜的機率 越小越好(越接近 ),這樣 才會大,分數才會高。」
最大概似估計 (MLE) 的目標,就是要「最大化」這個函數。白話來說,就是想盡辦法讓機器「對正確答案充滿自信」。
我們要想辦法最大化這個函數,用的方法是——你猜對了——梯度下降。算出來的更新規則跟線性迴歸的簡直像得出奇:
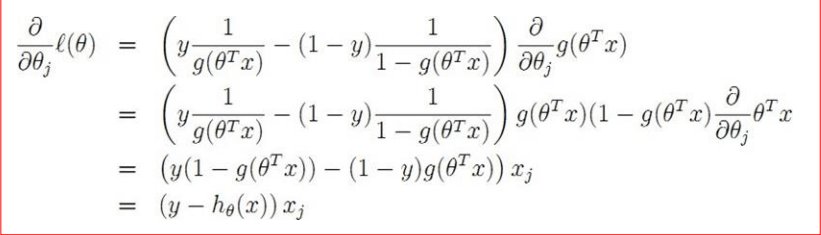
公式長得一模一樣,但別忘了,這裡的
總結
| 主題 | 核心概念 |
|---|---|
| 資料前處理 | 在訓練模型前,清理並轉換原始資料。 |
| 線性迴歸 | 用線性模型來預測連續的數值。 |
| 成本函數 (J) | 衡量我們的預測錯得有多離譜。 |
| 梯度下降 | 透過迭代調整參數,想辦法把成本降到最低。 |
| 批量 vs 隨機 GD | 看完所有樣本才更新 vs 看完一筆樣本就更新。 |
| 欠擬合 / 過擬合 | 模型太簡單抓不到規律 vs 模型太複雜只會死背。 |
| 局部加權 LR | 預測時,給距離近的資料點比較大的影響力。 |
| 邏輯迴歸 | 使用 Sigmoid 函數來分類離散的結果 (如 0 或 1)。 |