決策樹是什麼?
決策樹就跟它的名字一樣,是一棵用來做決策的樹狀模型。每個內部節點會針對某個特徵提出一個問題,每條分支代表一個可能的答案,而每片葉子就是最終的分類結果。
來看一個經典例子:今天該不該去打網球?
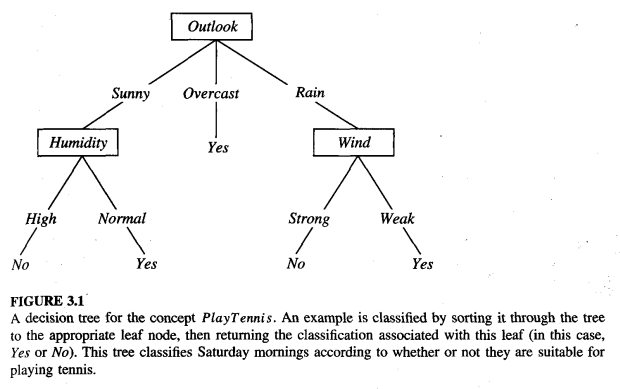
天氣狀況
/ | \
晴天 陰天 雨天
/ | \
濕度 Yes 風力
/ \ / \
高 正常 強 弱
/ \ / \
No Yes No Yes
這棵樹會先檢查天氣狀況。如果是陰天,什麼都不用管,去打球就對了(Yes);如果是晴天,就接著檢查濕度;如果是雨天,就看風速大不大。邏輯非常簡單又好懂對吧?
我們也可以把這棵樹寫成一組邏輯規則(叫做析取範式,disjunctive normal form):
- (天氣 = 晴天)∧(濕度 = 正常)→ Yes
- (天氣 = 陰天)→ Yes
- (天氣 = 雨天)∧(風力 = 弱)→ Yes
這也是決策樹最棒的地方之一:你永遠可以把它轉換成人類看得懂的 if-then 規則。
為什麼要用決策樹?
決策樹有幾個很不錯的特性,讓它很適合作為分類問題的入門方式:
- 離散和連續特徵都能處理。 像顏色(紅、藍、綠)這種離散特徵,決策樹處理起來很自然。至於像溫度這種連續數值,決策樹也能透過設定門檻來切分(例如:溫度 < 30°C vs. ≥ 30°C)。
- 天生就能表達「或(OR)」的邏輯。 有時候分類的界線是由多個條件組合而成的,決策樹處理這種情況得心應手。
- 對雜訊(Noise)有一定的容忍度。 就算資料裡有一些標記錯誤的樣本,或是特徵值有點誤差,它還是能運作得不錯。
- 能處理缺失值。 就算某筆資料少了某個特徵的值,演算法依然有辦法處理。
- 分為兩種:分類樹 (Classification trees) 會在葉節點輸出離散的類別標籤;而迴歸樹 (Regression trees) 則是預測出連續的實數值。
怎麼建構一棵決策樹?
建構決策樹的核心是一個「由上而下、遞迴、分而治之 (divide-and-conquer)」的過程。虛擬碼大概長這樣:
DTree(examples, features):
if 所有 examples 都屬於同一個類別:
return 一個標有該類別的葉節點
if 已經沒有 features 可以用了:
return 一個標有多數類別的葉節點
挑一個「最好的」特徵 F
為 F 建立一個節點
對 F 的每個可能值 v:
取出 F = v 的資料子集 (examples_v)
如果 examples_v 是空的:
接上一個標有 examples 多數類別的葉子
否則:
接上 DTree(examples_v, features - {F}) 的結果
回傳以這個節點為根的子樹
虛擬碼詳解
因為我看了好幾次都看不太懂,所以寫一個白話文版本,希望能幫助理解:
把建構決策樹想像成「在一個大箱子裡,把混在一起的水果分門別類」的過程。
守則一:已經分乾淨了,就直接貼標籤(結束)
對應虛擬碼:
if 所有 examples 都屬於同一個類別:return 葉節點
如果你現在看著眼前的這堆水果,發現「哇!裡面百分之百都是紅蘋果」,那你就不用再去想還要問什麼問題了。直接拿一張貼紙寫上「蘋果」貼上去,這堆水果的分類工作就完美結束。
守則二:問題問完了但還是混在一起,少數服從多數(結束)
對應虛擬碼:
if 已經沒有 features 可以用了:return 多數類別的葉節點
假設你手上只有三個問題能問:「是不是圓的?」、「是不是紅的?」、「是不是甜的?」。 如果你把這三個問題都問完了,把水果分到最後一小堆時,發現裡面還有「3 顆紅蘋果」跟「1 顆長得很像蘋果的紅芭樂」混在一起,但你已經沒有問題可以問了,怎麼辦? 沒辦法,只能妥協!既然蘋果佔多數,你就閉著眼睛給這堆水果貼上「蘋果」的標籤,結束這回合。
守則三:還沒分乾淨,就找個好問題切兩半,然後「重複守則」(繼續)
對應虛擬碼:
挑一個「最好的」特徵 F... 分子集... 接著呼叫 DTree(子集)
如果眼前的這堆水果還是蘋果、香蕉、芭樂大混雜,你就必須找一個最能把牠們區分開來的好問題。
- 你問:「是不是黃色的?」
- 你把水果分成兩堆:「是黃色的放左邊」、「不是黃色的放右邊」。
- 遞迴過程:
- 針對左邊那一堆,你假裝自己是剛上班,重新從「守則一」開始檢查這堆水果。
- 針對右邊那一堆,你也重新從「守則一」開始檢查這堆水果。
整個流程的關鍵問題就是:要怎麼挑「最好的」特徵?
熵 (Entropy) 與資訊增益 (Information Gain)
這裡就要請出資訊理論了。我們的目標是選一個能把資料分得最「乾淨」的特徵,也就是讓每個分支盡可能只剩下單一類別。
熵(Entropy)
熵衡量的是一個集合的混亂程度或不純度。以二元分類來說:
其中
公式詳解
我們把這個公式一步一步才開,看看到底是什麼意思?
第一步:
這最簡單。它們就只是「比例」而已(所有的比例加起來要是 1)。
假設箱子裡只有「蘋果 (1)」和「香蕉 (0)」:
= 蘋果佔的比例。 = 香蕉佔的比例。 - 如果一半一半,那
, 。
第二步:
公式裡最煩人的就是這個
請直接把它翻譯成白話文:「為了解決一個發生機率是
數學家發現了一個規律:
- 如果抽中蘋果的機率是 50% (
),你需要問 1 個問題。在數學上: 。 - 如果抽中葡萄的機率只有 25% (
),因為它比較稀有、比較難找,你需要問 2 個問題。在數學上: 。 - 如果機率是 100% (
),你根本不用問。在數學上: 。
所以,
第三步:為什麼要「相乘」又「相加」?
公式是長這樣的:
這在數學上叫做「加權平均數」。因為你每次伸手進去抽,有時候抽到蘋果,有時候抽到香蕉,所以我們要把所有的情況平均起來看。
整句公式的白話文翻譯就是:
(抽中蘋果的機率
直覺上怎麼理解:
- 如果所有樣本都是同一類 → 熵 = 0(完全純淨,沒有不確定性)
- 如果樣本剛好正反各半(50/50)→ 熵 = 1(最大的不確定性)
如果是包含
就只是第一個公式加了一個Sigma(
你可以把熵想成:如果隨機抽一筆資料,平均需要幾個 bit 才能表達它的類別。越不確定,需要的 bit 就越多。
或者這麼說:如果你閉著眼睛從箱子裡隨機抽一顆水果,你平均需要問幾個『是非題』,才能100%確定你抽到的是什麼水果。
- 如果你什麼都不用問就知道答案 -> 不確定性極低 -> 熵為 0。
- 如果你要問很多個問題才能找出答案 -> 不確定性很高 -> 熵很大。
資訊增益(Information Gain)
資訊增益衡量的是:用某個特徵做分割之後,熵減少了多少(也就是不確定性降低了多少)。
其中
這玩意太難懂了,所以英文是:where
is the subset of where feature has value .
公式詳解
我們把公式拆開來看,它其實就是一個簡單的減法:【原本要問的問題數】-【問完之後,剩下還要問的問題數】
1. 減號前面的
這是分割前,整個大箱子
- 白話文: 在你問任何問題之前,如果你閉著眼睛抽一顆水果,平均需要問幾個是非題?(例如原本很亂,需要問 2 個問題)。
2. 減號後面的那一長串:分割後的「加權平均」混亂度
這一串
為什麼要乘上
這叫做加權平均。想像你把 100 顆水果用「是不是紅色?」切成兩堆:
- 左邊堆(紅色): 有 99 顆,裡面有蘋果也有小番茄,很亂(Entropy 很高)。
- 右邊堆(不是紅色): 只有 1 顆,剛好是黃色香蕉,很純(Entropy = 0)。
因為左邊那堆佔了絕大多數(99%),所以你下一次伸手抽水果,有 99% 的機率會抽到左邊那堆,你還是得面對很高的混亂度。因此,哪一堆的水果數量越多,它對整體混亂度的影響力(權重)就應該越大。
= 這小堆水果佔整個箱子的比例。 = 這小堆水果自己的混亂度(還要問幾個問題)。
白話來說:資訊增益 = 分割前的熵 − 分割後各子集熵的加權平均。資訊增益最高的那個特徵就是我們的首選。
實際算一次
來看四筆資料,特徵是(大小、顏色、形狀),分類是正(+)或負(−):
| 編號 | 大小 | 顏色 | 形狀 | 類別 |
|---|---|---|---|---|
| 1 | 大 | 紅 | 圓形 | + |
| 2 | 小 | 紅 | 圓形 | + |
| 3 | 小 | 紅 | 方形 | − |
| 4 | 大 | 藍 | 圓形 | − |
整組資料有 2 正 2 負,所以
用大小來分:
- 大 → 1+, 1− →
- 小 → 1+, 1− →
— 完全沒用!
用顏色來分:
- 紅 → 2+, 1− →
- 藍 → 0+, 1− →
— 好多了。
用形狀來分:
- 圓形 → 2+, 1− →
- 方形 → 0+, 1− →
— 跟顏色一樣好。
所以第一刀我們會選顏色或形狀(兩者 gain 都是 0.311),絕對不會選大小(gain = 0)。
ID3 演算法
我們一直在講的這個方法,正式名稱叫做 ID3,是 J. Ross Quinlan 在 1979 年發明的。它巧妙地運用了 Shannon 的資訊理論 (1948) 來挑選特徵。它的幾個重要特色包含:
- 採用由上而下 (top-down) 建構,不走回頭路 (no backtracking)。
- 每一步都貪心地選擇資訊增益最高的特徵。
- 在非葉節點的分支上遞迴執行,直到所有資料都被分類完畢。
- 會搜尋整個資料集來建構這棵樹。
後來這個演算法被改良成了 C4.5 (Quinlan, 1993),可以處理連續數值、缺失值,還加入了剪枝機制。同一時期,Breiman 和 Friedman 也開發了另一個很有名的平行發展演算法,叫做 CART (Classification and Regression Trees)。
有趣的例子:辛普森家庭角色分類
假設我們想用三個特徵(頭髮長度、體重、年齡)來分類辛普森家庭的角色是男是女。
| 角色 | 頭髮長度 (吋) | 體重 (磅) | 年齡 | 性別 |
|---|---|---|---|---|
| Homer | 0" | 250 | 36 | M |
| Marge | 10" | 150 | 34 | F |
| Bart | 2" | 90 | 10 | M |
| Lisa | 6" | 78 | 8 | F |
| Maggie | 4" | 20 | 1 | F |
| Abe | 1" | 170 | 70 | M |
| Selma | 8" | 160 | 41 | F |
| Otto | 10" | 180 | 38 | M |
| Krusty | 6" | 200 | 45 | M |
資料裡有 4 女 5 男,初始的
我們計算每個特徵的資訊增益來找最佳切分點:
- 頭髮長度 ≤ 5? → Gain = 0.0911
- 體重 ≤ 160? → Gain = 0.5900 ← 贏了!
- 年齡 ≤ 40? → Gain = 0.0183
「體重」給了我們最棒的切分。所有體重超過 160 磅的角色都是男生(這條分支的熵 = 0,搞定!)。但體重 ≤ 160 的群體裡還是混雜著 (4女, 1男),所以我們要繼續往下遞迴。
在第二次切分時,我們發現 頭髮長度 ≤ 2 完美地把剩下的人分開了:Bart(短頭髮,男生)對上其他女生(長頭髮)。
最終的決策樹:
體重 ≤ 160?
/ \
是 否
/ \
頭髮長度 ≤ 2? 男性
/ \
是 否
/ \
男性 女性
寫成規則就是:
- 如果體重 > 160 → 男性
- 否則如果頭髮長度 ≤ 2 → 男性
- 否則 → 女性
現在如果「漫畫男 (Comic Book Guy)」出現了(頭髮: 8", 體重: 290, 年齡: 38),決策樹會判斷:體重 290 > 160 → 男生。完全正確!
過擬合問題
不過有個陷阱:一棵能完美分對所有訓練資料的樹,不見得就是一棵好樹。
過擬合(Overfitting) 就是模型把訓練資料學得「太好了」——連雜訊和偶然的巧合都一起學進去了——結果在新資料上反而表現更差。正式地說,如果存在另一個假設
打個比方:假設你要驗證歐姆定律
決策樹也是一樣的道理。資料裡的雜訊會讓演算法多長出一些不必要的分支,這些分支只是捕捉到了隨機性,不是真正的規律。
雜訊怎麼造成過擬合
回到前面顏色/形狀的例子,假設有一筆訓練資料被標錯了。為了把這一筆也分對,決策樹可能需要額外用一些不相關的特徵(像大小)來多分幾層。結果就是一棵更大、更複雜,但泛化能力更差的樹。
剪枝 (Pruning):過擬合的解藥
要解決過度擬合,主要有兩種策略:
預剪枝(Prepruning) — 在樹還沒完全長滿之前,就提早喊停。例如,當某個節點的資料量太少,覺得切分下去不可靠時,就不切了。
後剪枝(Postpruning) — 先讓整棵樹長好長滿,然後再把那些對「泛化能力(面對新資料的能力)」沒有幫助的樹枝剪掉。通常這種方法比較有效,因為實務上我們很難預測什麼時候該提早喊停。
簡化誤差剪枝(Reduced Error Pruning)
這是一種很常見的事後剪枝法:
- 把你的資料分成「生長集 (grow set)」和「驗證集 (validation set)」。
- 用生長集建構一棵完整的決策樹。
- 針對每一個內部節點,試著把它的子樹整個拔掉,變成一個葉節點(類別就用該節點的多數決)。
- 如果拔掉之後,模型在驗證集上的準確率提升了(或沒變差),就永遠剪掉它。
- 重複這個動作,直到再剪下去準確率會掉為止。
這方法的缺點是你得「犧牲」一部分訓練資料拿去當驗證集。另一個替代方案是:跑好幾輪不同的隨機分割,記錄每次剪枝後的樹的複雜度,取平均值
其他剪枝方法
- 統計檢定 : 檢查節點上的資料規律是真的有統計顯著性,還是只是隨機出現的。
- 最小描述長度(MDL) : 權衡一下:「多長出這些樹枝的複雜度」跟「直接把例外情況死記下來」,哪一個比較划算?
運算複雜度 (Computational Complexity)
在最壞的情況下(長出一棵完整的樹,而且每條路徑都測試了所有特徵),建構決策樹需要花費
但實際上,樹很少會長到那麼完整,通常時間複雜度跟
優點與限制
優點
- 能產出人類可以直接看懂的解釋規則。
- 訓練速度快,預測新資料的速度也很快。
- 數值型跟類別型的特徵都能無痛處理。
- 對雜訊跟缺失值有不錯的容忍度。
- 不需要先做特徵縮放 (Feature scaling) 或正規化。
限制
- 非常容易過度擬合 (Overfitting),特別是在資料量很小的時候。
- 一次只能測試一個特徵(只能切出平行於坐標軸的邊界),很難捕捉到對角線或傾斜的決策邊界。
- 資訊增益演算法天生會偏袒那些「擁有很多種不同數值」的特徵。
- 貪心演算法沒辦法保證你能找到「全域最佳」的樹(事實上,要找到最小且一致的樹是一個 NP-hard 問題)。
- 只能給出絕對的分類結果,沒辦法告訴你它有「多大機率」或「多大信心」覺得是這個類別。
接下來呢?
學會決策樹後,其實你已經為學習更強大的演算法打下了基礎:
- 隨機森林 (Random Forests) — 隨機挑選資料和特徵,建構出一大堆決策樹,最後大家一起投票表決。
- 梯度提升樹 (Gradient Boosted Trees,像是 XGBoost, LightGBM) — 也是種一堆樹,但它們是循序漸進的,每一棵新樹都在努力修正前一棵樹犯的錯誤。
- C4.5 / C5.0 — Quinlan 對 ID3 的升級版,更聰明地處理連續特徵、缺失值和剪枝。
這些「集成學習 (Ensemble)」的方法,是目前業界在處理結構化表格資料時最成功也最常勝的演算法——而它們全都是建立在我們今天學到的決策樹概念之上!